babel따라가보기(feat webapck, babel-loader)
보통 웹팩에서는 바벨컴파일링을 사용하여 리액트 코드를 변환한다.
간단한 jsx변환을 위해 바벨에서는 어떤 일들을 하는지 디버깅 해보자
##웹팩 빌드 디버깅
#테스트를 위한 웹팩 설정
바벨을 사용하기 위해 웹팩설정
module.exports = {
test: /\.(js|jsx|ts|tsx)?$/,
exclude: /node_modules/,
use: {
loader: 'babel-loader',
options: {
presets: [
'@babel/preset-react',
],
},
},
};
##node_modules 내 소스 변경
babel-loader는 transform시에 캐쉬를 남겨놓기 때문에 변경사항이 없으면 트랜스폼 과정없이 캐쉬파일이 결과물이 된다.
따라서 아래같이 node_modules내 소스를 수정하여 캐쉬파일을 사용안하도록 한다. 아니면 매번 node_modules/.cache 에서 바벨관련 캐쉬를 매번 지워야한다.
// node_modules/babel-loader/lib/index.js
// 170 라인쯤?
const {
cacheDirectory = null,
cacheIdentifier = JSON.stringify({
options,
"@babel/core": transform.version,
"@babel/loader": version
}),
cacheCompression = true,
metadataSubscribers = []
} = loaderOptions;
let result;
// 캐쉬디렉토리가 있는지 체크하는 부분을 false로 변경하여 항상 transform 메소드를 실행하도록 한다.
if (false) {
result = yield cache({
source,
options,
transform,
cacheDirectory,
cacheIdentifier,
cacheCompression
});
} else {
result = yield transform(source, options);
}
#바벨로 변경될 소스
바벨 프로세스 추적을 용이하기 위해 코드는 최대한 간소화한 jsx를 사용하였다.
// index.js
const App = () => <div>홀홀</div>;
프로젝트 루트에서 node-nightly를 이용하면 노드프로세스를 chrome developer툴로 디버깅 가능하다.
// 웹팩과 바벨로더를 통하는경우(이 글에서의 경우)
node-nightly --inspect-brk ./node_modules/webpack/bin/webpack.js
// 직접 바벨만 돌리는경우
node-nightly --inspect-brk ./node_modules/.bin/babel src --out-dir dist
chrome://inspect 접속
디버깅방법 참고 : webpack bits: Learn and Debug webpack with Chrome Dev Tools!
#바벨로더가 호출되는 과정 트레이싱(node_modules가 루트)
많은 프로세스가 진행되지만 그중 몇부분만 브레이크포인트 잡아보았다.직접 돌려보기 바란다.
webpack/bin/webpack.js -> webpack-cli/bin/cli.js -> webpack/lib/Compiler.js -> webpack/lib/Compilation.js -> webpack/lib/NormalModuleFactory.js -> webpack/lib/NormalModule.js
NormalModule 객체 생성시 loaders 멤버에 babel-loader가 들어간다. 그 후 doBuild 메소드를 통해 babel-lodaer의 loader메소드가 반환되고 loader-runner 모듈을 통해 실행된다.
#Chrome Dev tool 화면
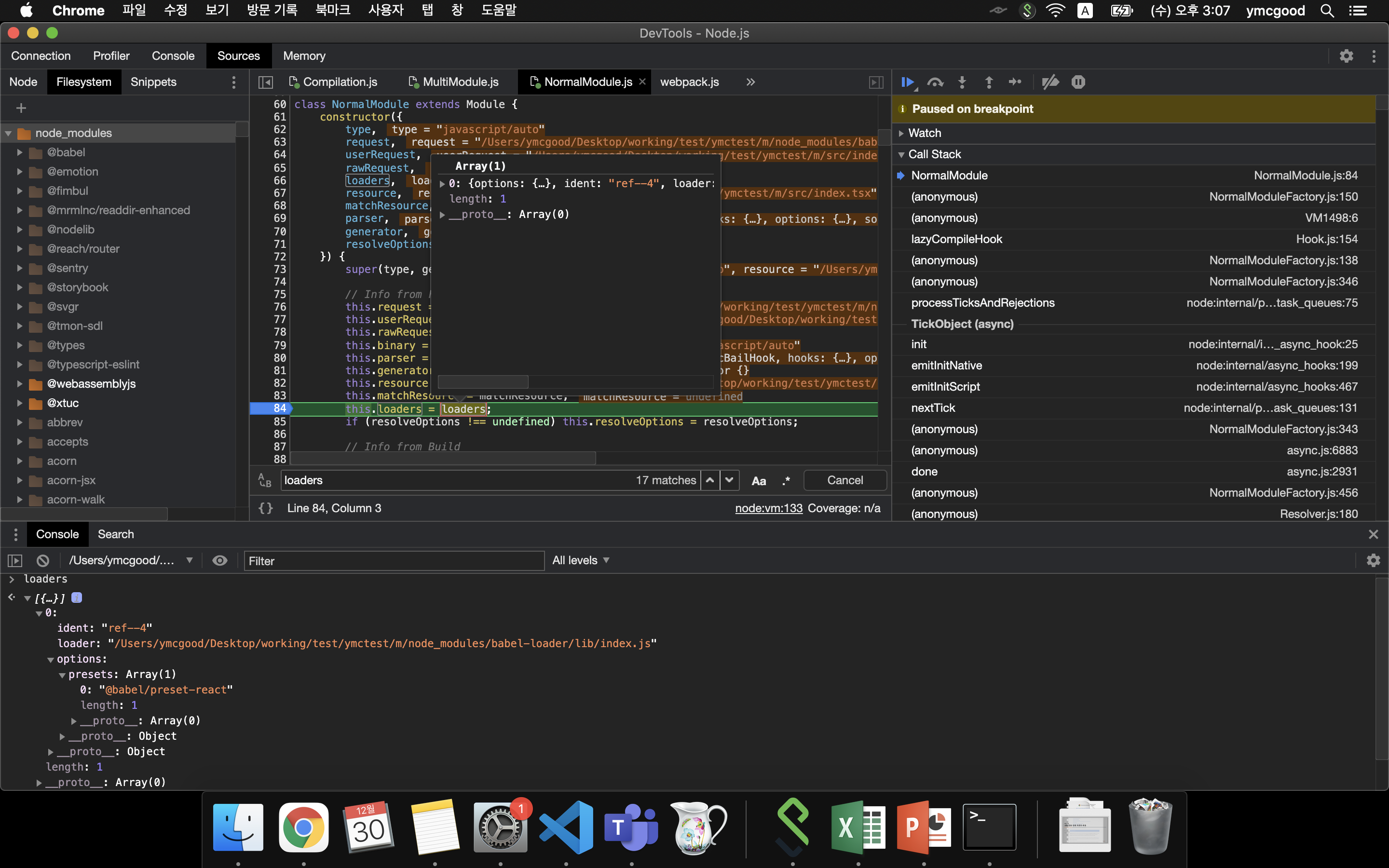
#이제 babel 동작과정을 살펴보자
그전에 아래 링크를 먼저 보면 좋다. 바벨팀에서 직접 설명하는 영상이다.
바벨동작과정 : @babel/how-to
위 영상을 보면 알수 있듯이 바벨의 처리과정은 크게 3부분으로 나눌수 있다.
1. parse
2. traverse
3. generate
babel-loader/lib/index.js -> babel-loader/lib/transform.js -> @babel/core/lib/transform.js -> @babel/core/lib/transform.js -> @babel/core/lib/transformation/index.js -> @babel/core/lib/transformation/normalize-file.js
normalize-file.js에서 parser 호출하는 부분이다.
#parser 호출
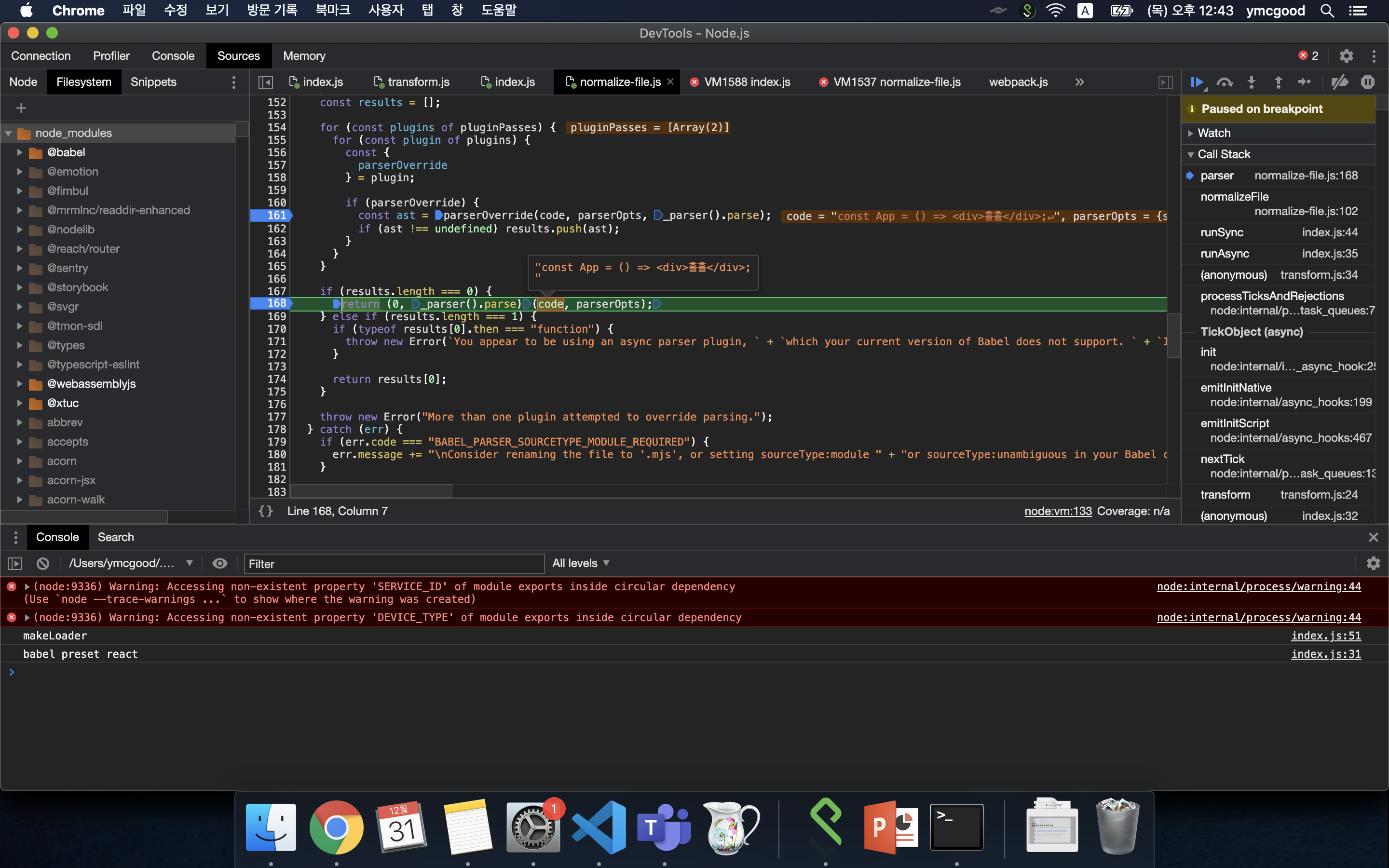
#parser 모듈 세팅
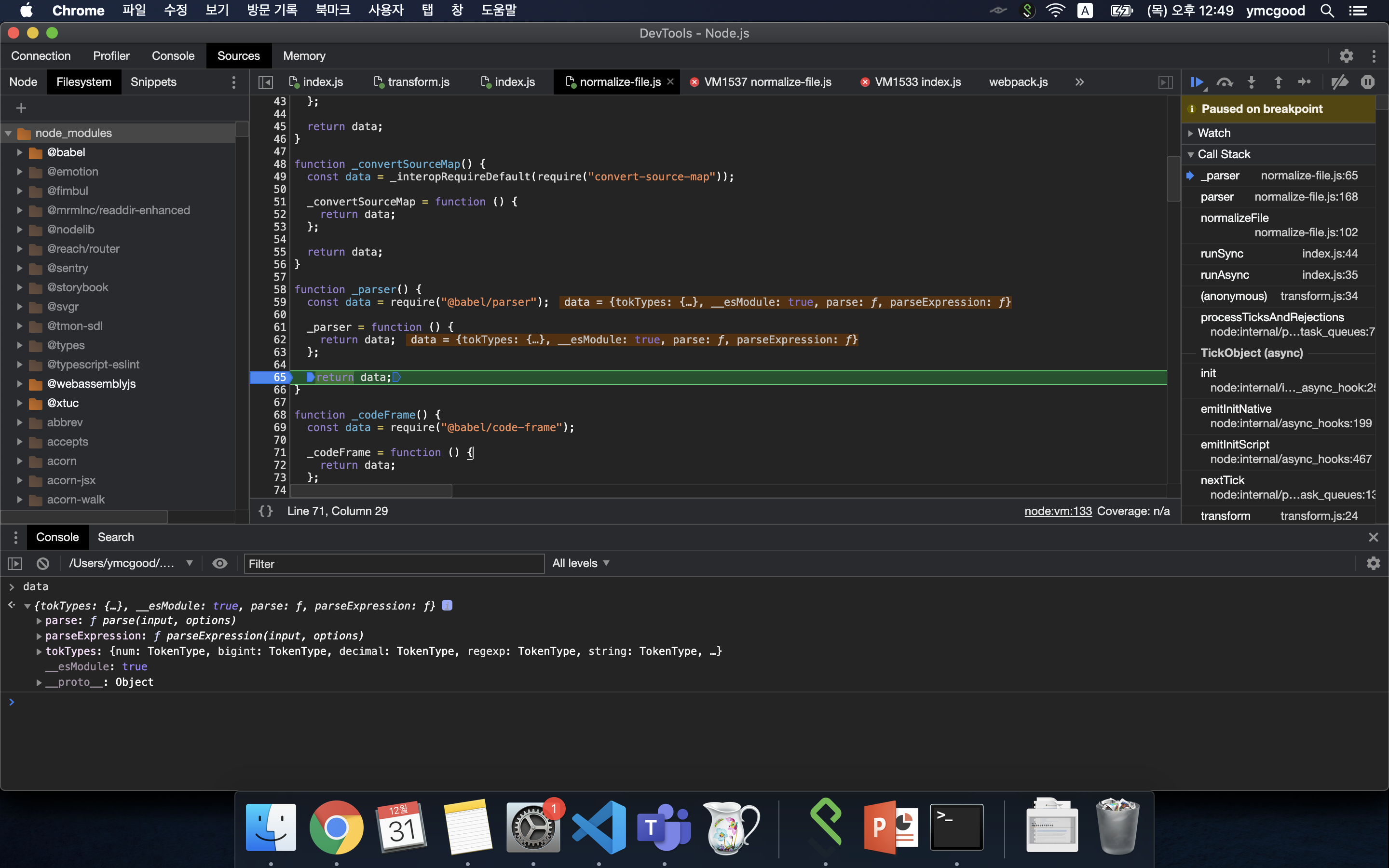
1. parse : 텍스트로 된 코드를 node로 된 ast(abstract syntax tree)로 바꾸는 과정
node_modudules안에 @babel/pareser/lib/index.js파일은 만줄이 넘는 코드로 합쳐져 있다. 다행히 index.map.js 파일이 있어 실제 디버깅하면 나눠진 파일로 볼수 있으나 flow로 작성되있어서 디버깅이 쉽진 않다. (sourceMap 파일을 지우면 원본파일이 디버깅 되어 브레이크 포인트를 잡을수 있다).나는 브레이크 포인트와 함께 babel 공식 github 소스도 보고 console을 찍어보며 따라가 보았다.
babel이 node로 된 ast를 만드는 시작점이다. : babel-parser 깃허브 소스
@babel/parser/lib/index.js의 parse() 함수가 실행된다. parse 함수 안에서는 getParser에서 StatementParser를 상속받은 Parser를 선택하고 Parser의parse를 호출한다.
#parser의 parse
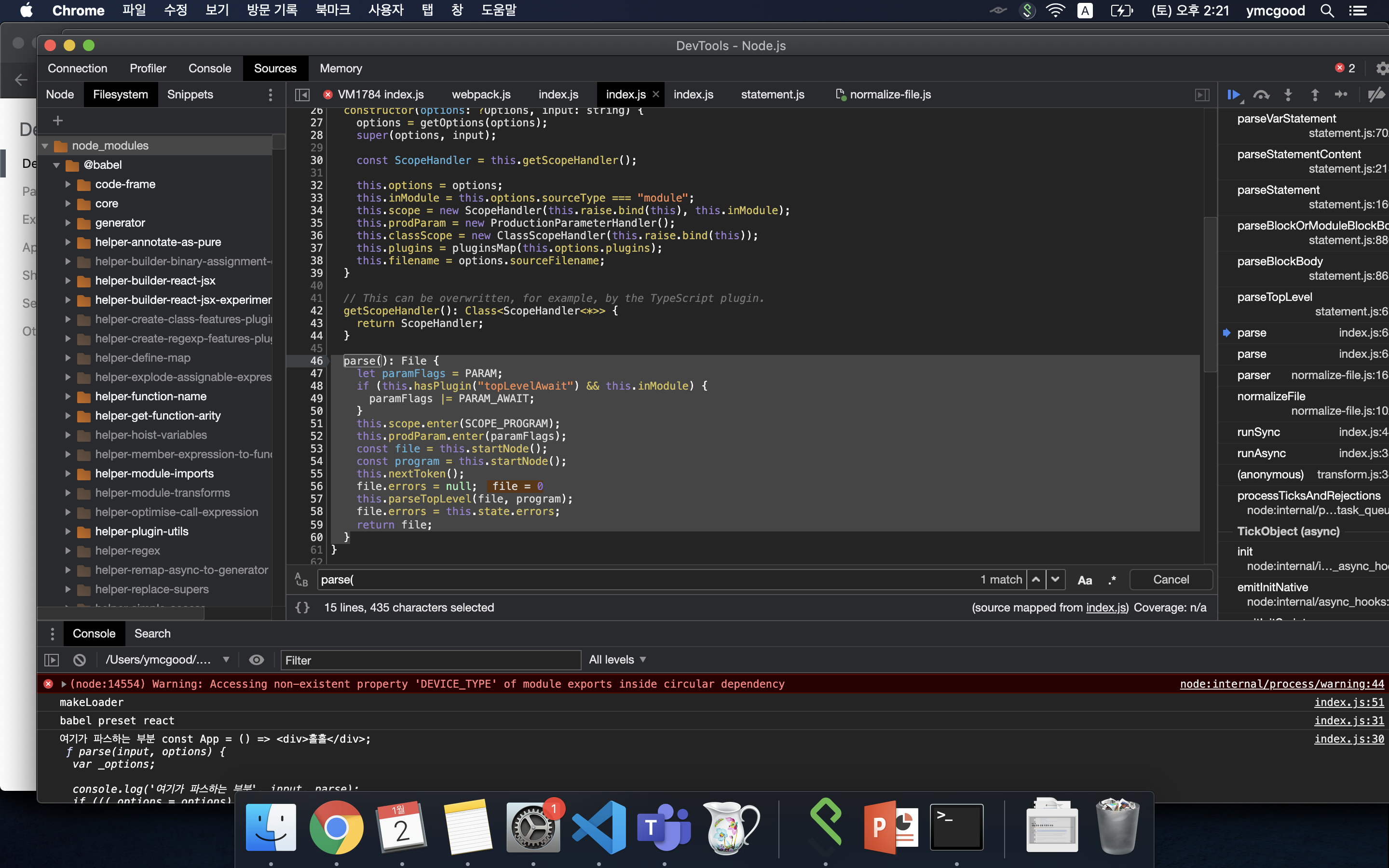
깃허브 원본소스: [parser의 parse] (https://github.com/babel/babel/blob/main/packages/babel-parser/src/parser/index.js#L48
Parser클래스는 baseParser부터 시작하여 기능을 확장해가며 생서된 클래스이다. 작고 비교적 간단한 기능부터 확장해나가며 클래스를 상속해나가는 구조이다.최초의 조상은 baseParser이다.
BaseParser -> CommentsParser -> ParserError -> Tokenizer -> UtilParser -> NodeUtils -> LValParser -> ExpressionParser -> StatementParser -> Parser (-> babel-parser/src/plugins/jsx/index.js parser를 슈퍼 클래스로 갖는 JSX 플러그인이 사용된다)
플러그인이 사용되는 과정은 babel-core/src/transformation/normalize-opts.js에서 config의 plugin들에 따라서 결정된다. 자세히 다루지는 않으나 밑에 @babel/helper-builder-react-jsx가 호출되는 부분과 연관이 깊어보인다. 직접 따라가 보기 바란다.
Parser의 parse함수의 리턴타입은 File객체이다. File객체 링크 : File객체
tokenizer의 nextToken함수로 문자들을 토큰화 한다. 문자 하나씩 아스키 코드로 받으면서 그 문자에 대한 방대한 swith문으로 처리된다.
예를들면 이 소스의 처음인 const의 경우 c로 시작되서 아스키 코드 99이다. 이경우 스위치문에서 readword라는 메소드를 실행하고 토큰을 얻는다. const에 대한 토큰 타입은 이미 하드코딩 되있다.
토큰타입들 : const 토큰타입
처리하면서 현재 분석중인 텍스트에 대한 위치는 state로 표현된다. this.state를 console찍어보면 알수 있다. 첫 토큰화가 끝나면 next() 등의 메소드를 통하여 다음 토큰을 만든다.
#tokenizer process
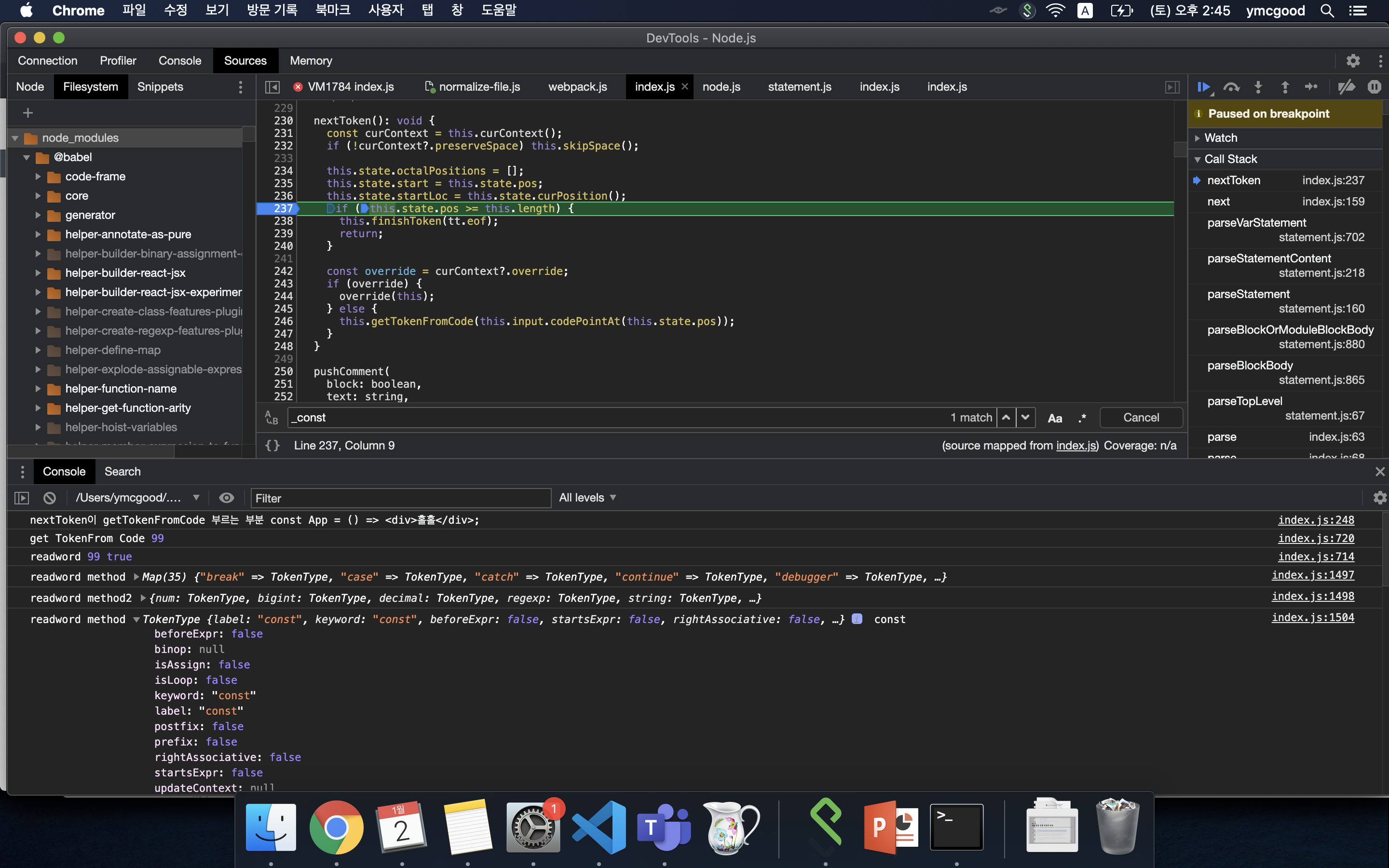
이 예제에서는 jsx plugin이 사용되어서 this.getTokenFromCode이 jsx plugin 객체의 것이다.
이 함수내에서 const와 같은 키워드는 super.getTokenFromCode가 호출되고 super는 Parser이다.
jsx 구문은 tokContext의 token값에 따라 여는 태그 <tag , 닫는 태그 </tag , 태그내 내용
#jsx tokenixer
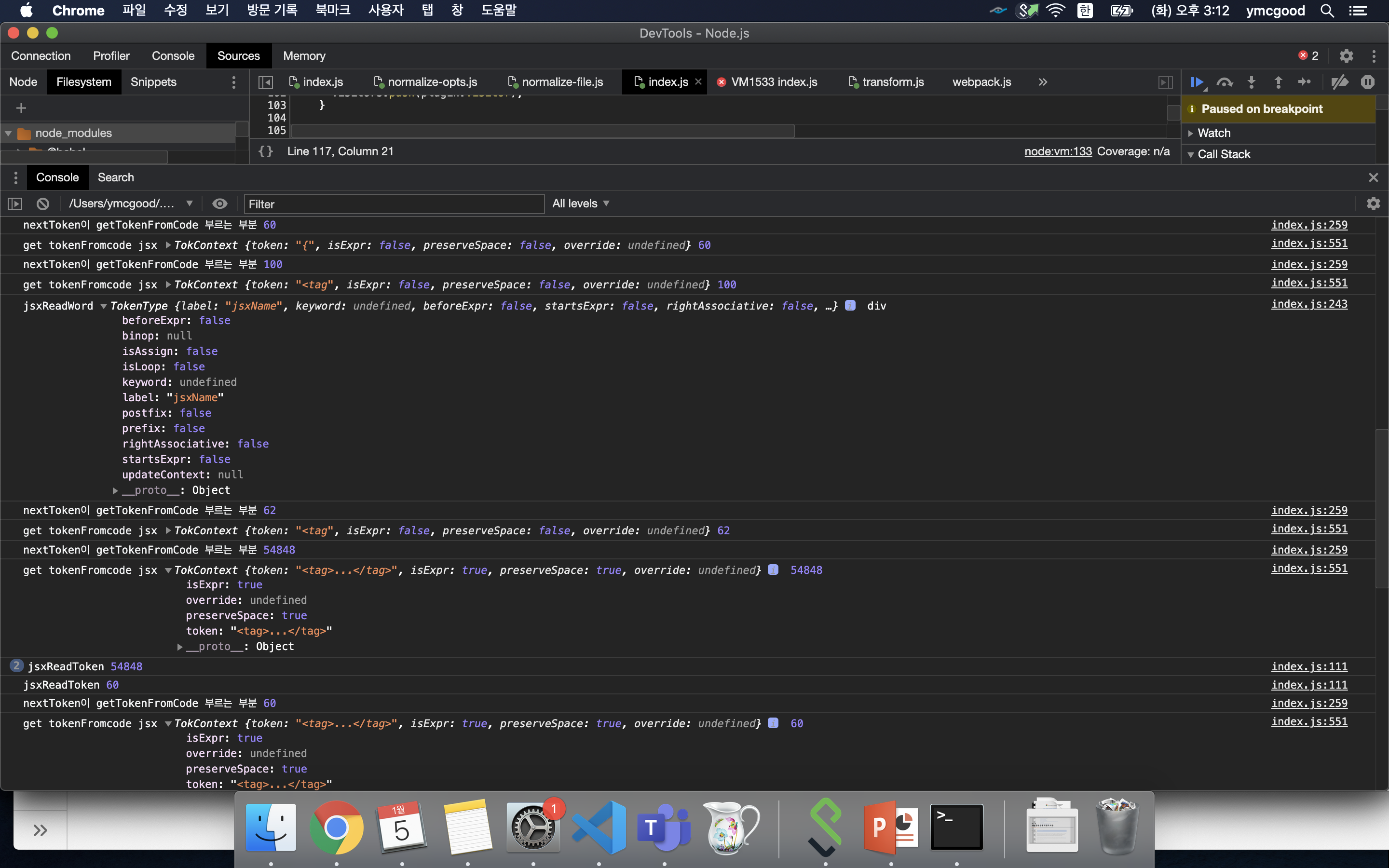
소스가 파싱되는과정은 처음 nextToken 호출시 const 토큰화 -> parseTopLevel -> parseBlockBody -> parseBlockOrModuleBlockBody -> parseStatement -> parseStatementContent -> 첫 토큰이 const이기에 parseVarStatement -> next 호출로 App(label:name) 토큰화 -> parseVar -> parseVarId -> parseBindingAtom -> parseIdentifier -> parseIdentifierName -> next로 “=” 읽음 -> eat호출 -> next로 “(“ 읽음 -> parseMaybeAssign -> parseMaybeConditional -> parseExprOps -> parseMaybeUnary -> parseUpdate -> parseExprSubscripts -> parseExprAtom -> parseParenAndDistinguishExpression -> next로 “)” 읽음 -> expect -> eat -> next로 “=” 읽음 -> shouldParseArrow -> parseArrow -> shouldParseArrow 와 parseArrow 를 통해 화살표 함수임을 체크 이과정에서 next를 통해 “<” 읽음 -> parseArrowExpression -> parseFunctionBody -> (parseMaybeAssign ~ parseExprAtom) 분기에서 jsxTagStart이므로 jsxParseElement -> jsx부분은 jsx plugin Parser에서 next를 호출해가며 파싱 완료한다…
콘솔에 parse전 비어있는 node를 찍어놨다 finishNode 시점과 비교 가능하다.
#parseStatement의 결과물
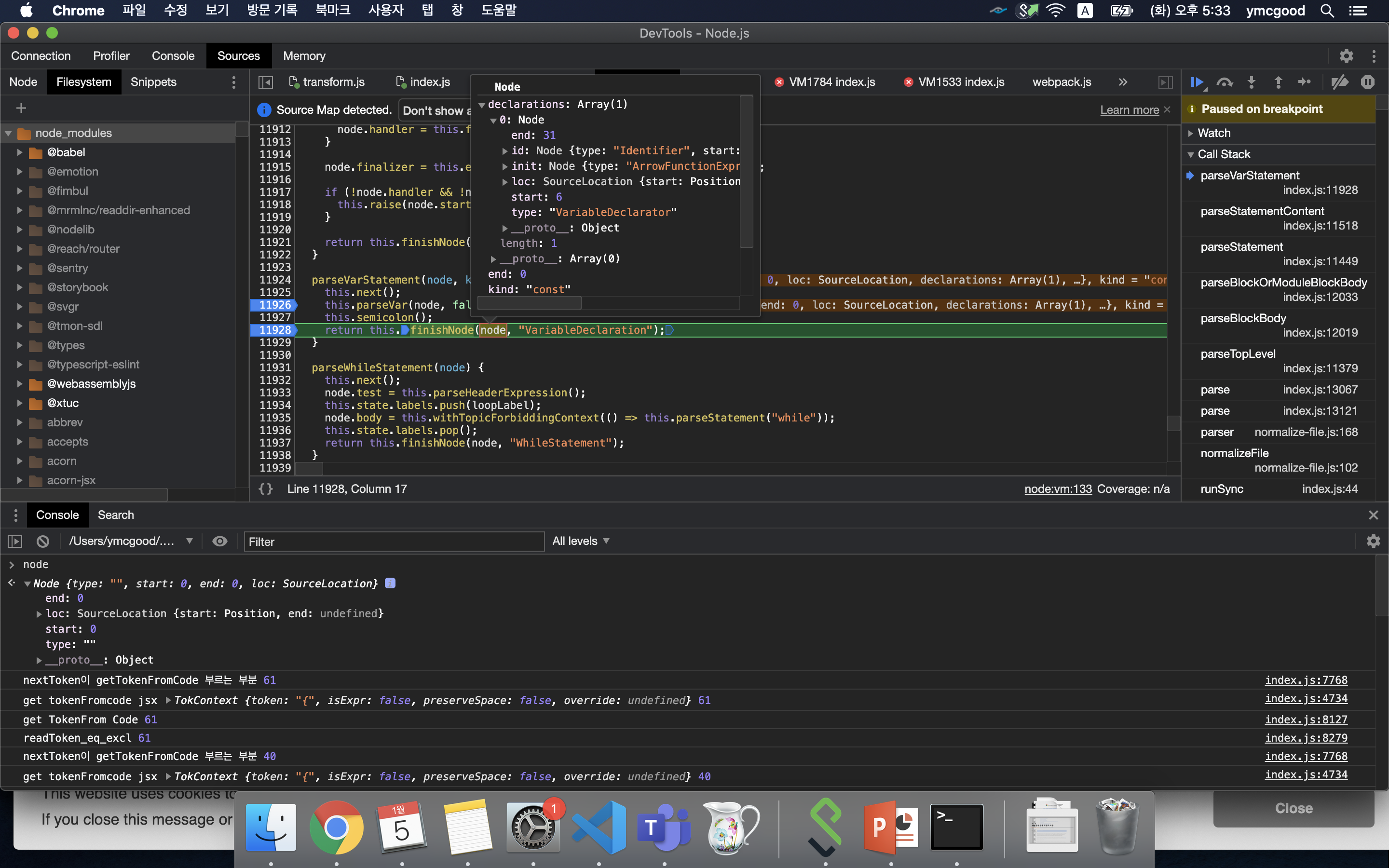
최종적으로는 file.prgram.body에 이 node가 들어가게 된다(File 타입은 ast의 최상위 node). 이때 body는 node들의 array인데 이 array의 length는 index.js의 문의 갯수와 같다. 만약 import문과 export문을 추가 하면 body.length는 3이다.
생성된 ast와 코드 원본 옵션 등을 이용하여 최상위 File 객체를 만들게 된다.
#File 객체 생성
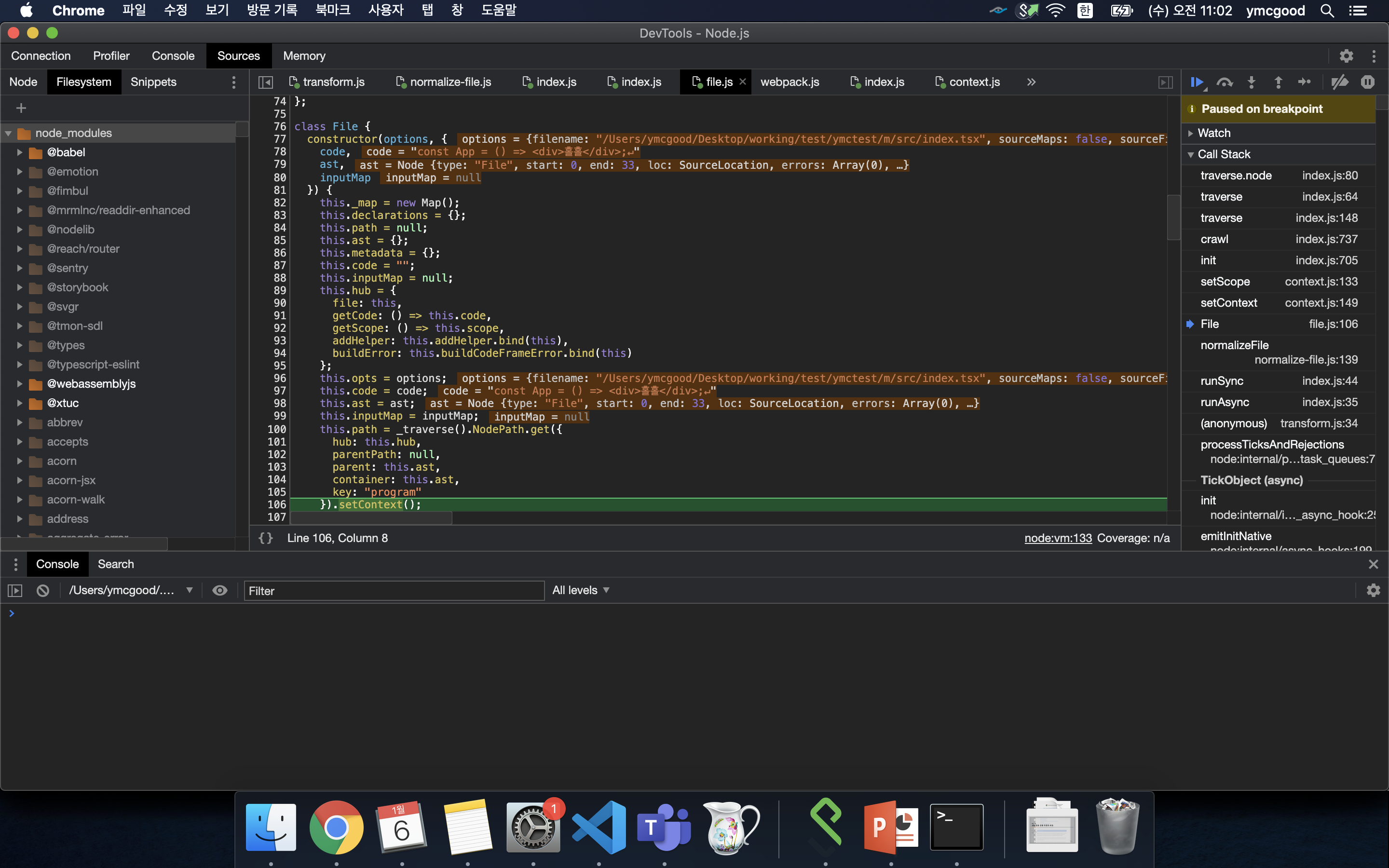
이때 생성된 File의 path를 세팅하기위해 1차적으로 node들을 traverse힌다.
2. traverse : 생성된 node들을 순회하며 필요한 작업 수행
위해서 언급한 path는 NodePath란 클래스로 생성된다.
path.traverse(collectorVisitor, state);
path를 세팅하면서 1차적으로 node들을 traverse할때 사용되는 visitor함수들은 collectorVisitor다.
visitor는 각 노드를 방문했을때 그 노드타입에따라 수행해야될 일이라 생각하면 된다.collectorVisitor를 통해 초기 scope를 만든다.
#초기 스코프
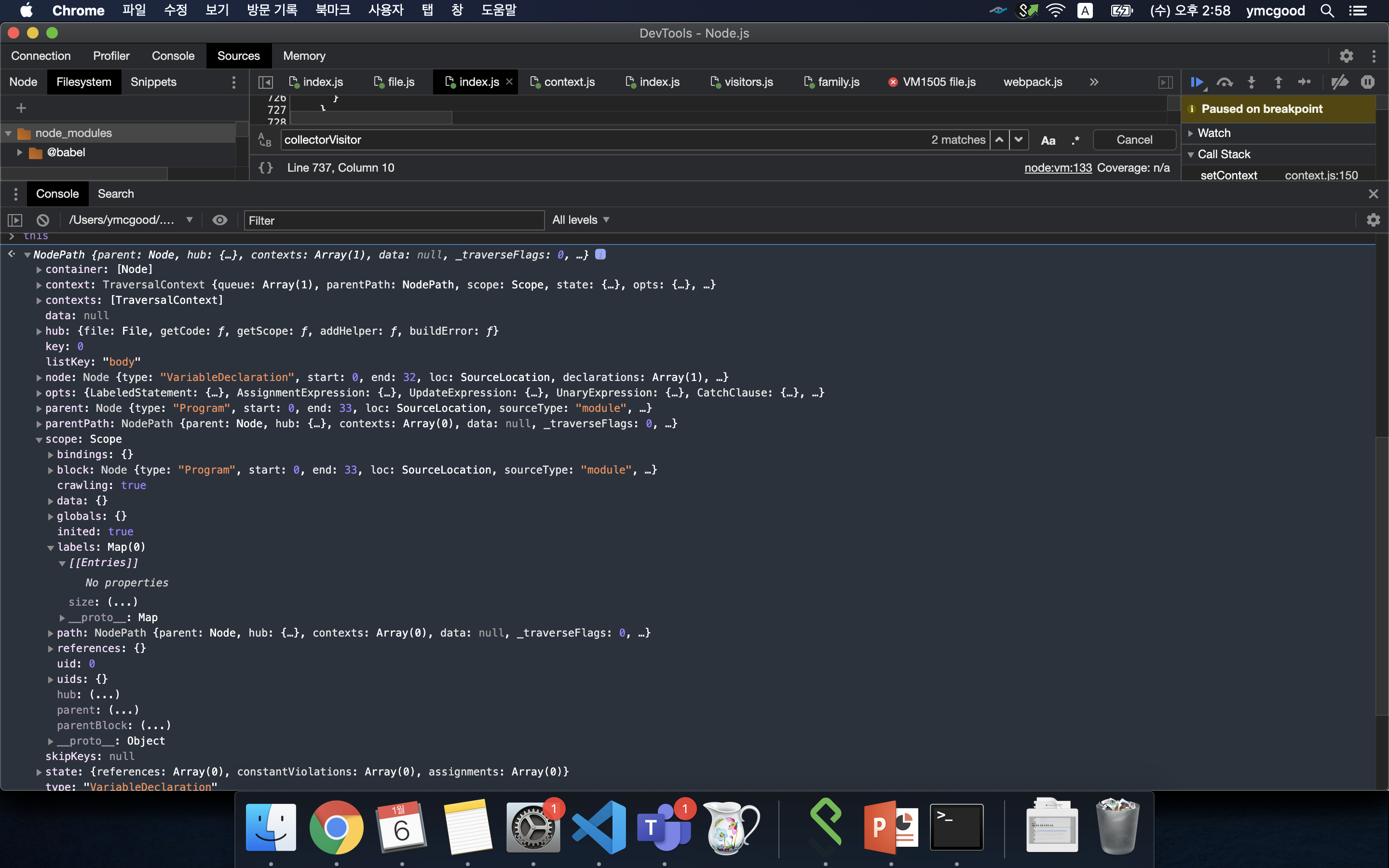
traverse는 깊이 우선 알고리즘 순회하고 node 방문때 enter단계, 노드의 자식까지 모두 방문하고 나오면 exit단계이다. 방문 node에 대한 작업은 enter 혹은 exit단계일때 이루어진다. 이는 노드 타입에 따라 다르다.
traverse 전과 후의 ast를 비교해보자
#traverse 전
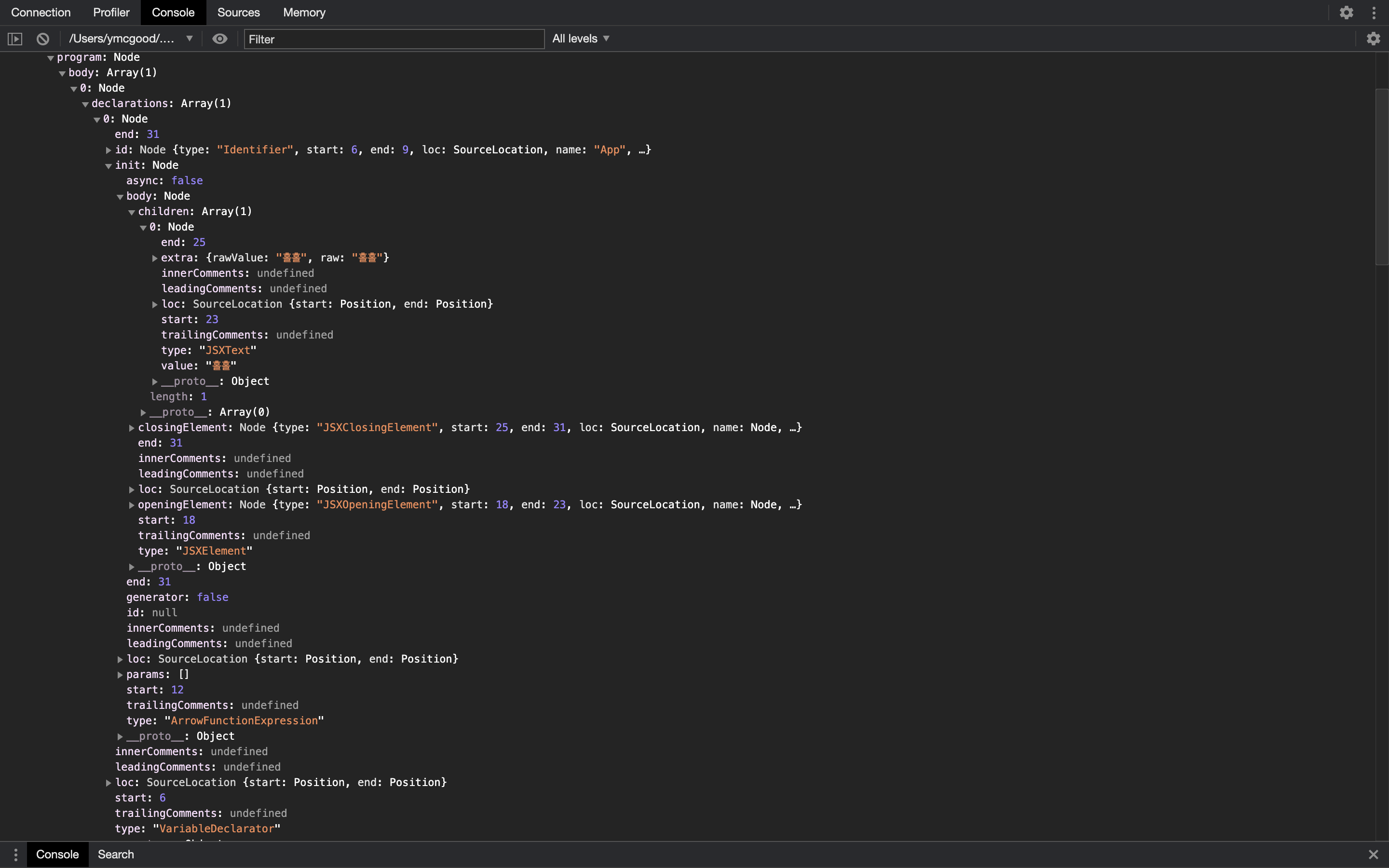
#traverse 후
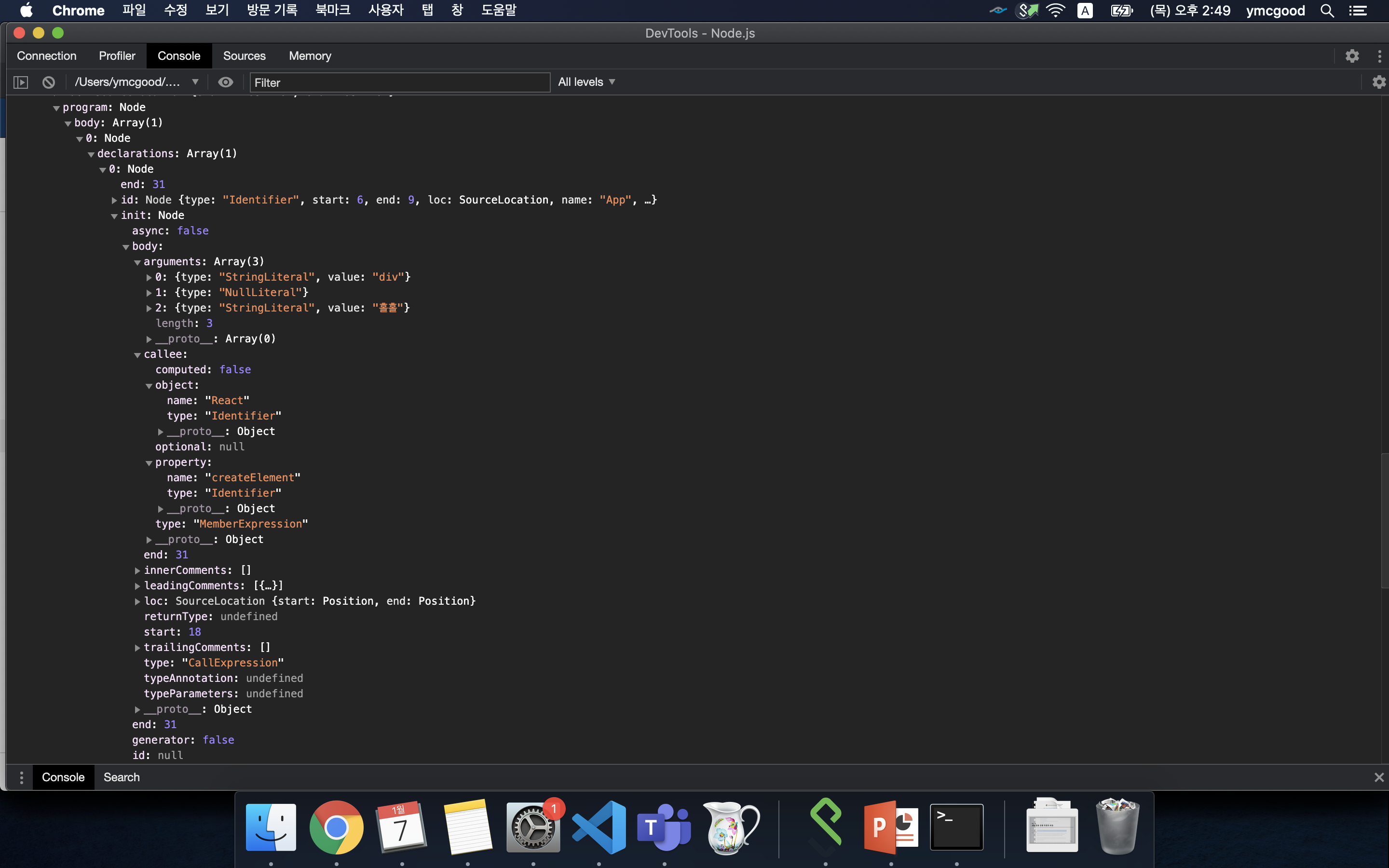
jsxElement가 React.createElement 함수 호출로 변환됬다.
이제 과정을 살펴보자
jsxElement 노드의 경우는 exit단계에서 작업이 이루어진다.
visit 메소드에서 exit단계에서 수행해야하는 함수를 call 한다.
#call
visitor.jsxElement도 확인할수 있다. exit시점에 동작하므로 exit메서드가 정의되 있다.
뜬금없이 babel-helper-builder-react-jsx 소스가 어떻게 visitor로 세팅되있는지 의아할 것이다. babel-loader 설정에서 ‘@babel/preset-react’를 사용하기로 하였다.
@babel/preset-react는 config를 로드하는 과정에서 호출되고 @babel/plugin-transform-react-jsx가 import된다.
#plugin-transform-react-jsx
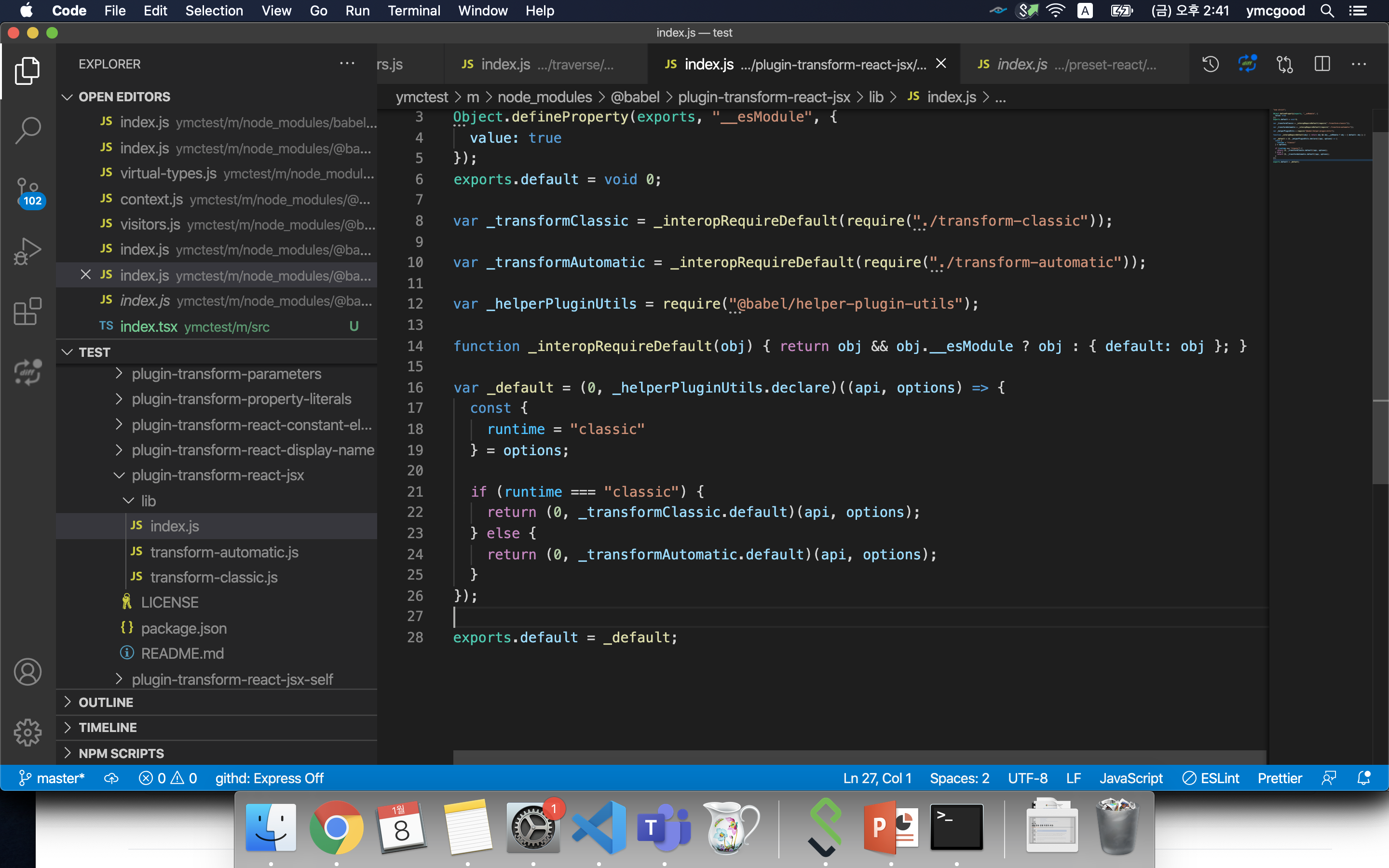
스크린샷을 보면 runtime 옵션에 따라 분기된다. default 값은 classic이므로 transform-classic.js 파일이 호출된다. 만약 babel-preset-env설정에 runtime: automatic으로 하면 “react/jsx-runtime”를 사용하여 react를 모든 파일에 import하지 않고도 jsx를 사용할수 있다. 이는 비교적 최신버전의 react와 babel버전에서 유효하므로 사용하고 싶다면 검색하여 버전을 체크하자.eslint는 “react/react-in-jsx-scope”: “off”로 설정하여 빨간줄 에러를 없앤다
#transfrom-classic
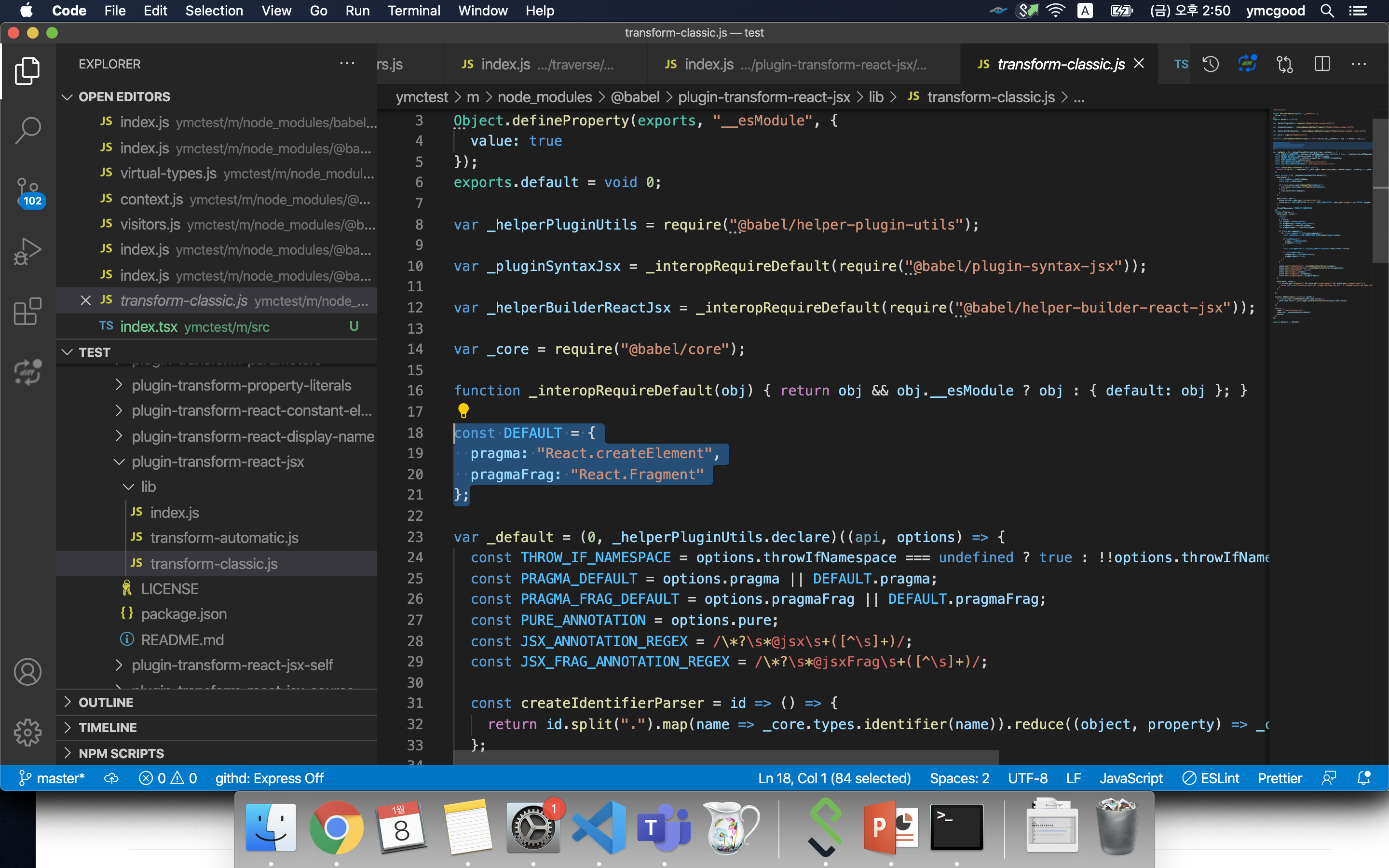 이 파일에서 jsx함수가 함수호출로 칠환될때 사용될 React.createElement를 확인할수 있다.
이 파일에서 jsx함수가 함수호출로 칠환될때 사용될 React.createElement를 확인할수 있다.
automatic인 경우는 react/jsx-runtime 의 jsx함수이다. @babel/helper-builder-react-jsx도 이 파일을 통해 visitor로 추가됨을 확인할수 있다.
@babel/traverse/lib/path/replacement.js 파일의 replaceWith에서 oldNode는 replacement로 대체된다.
#replacement
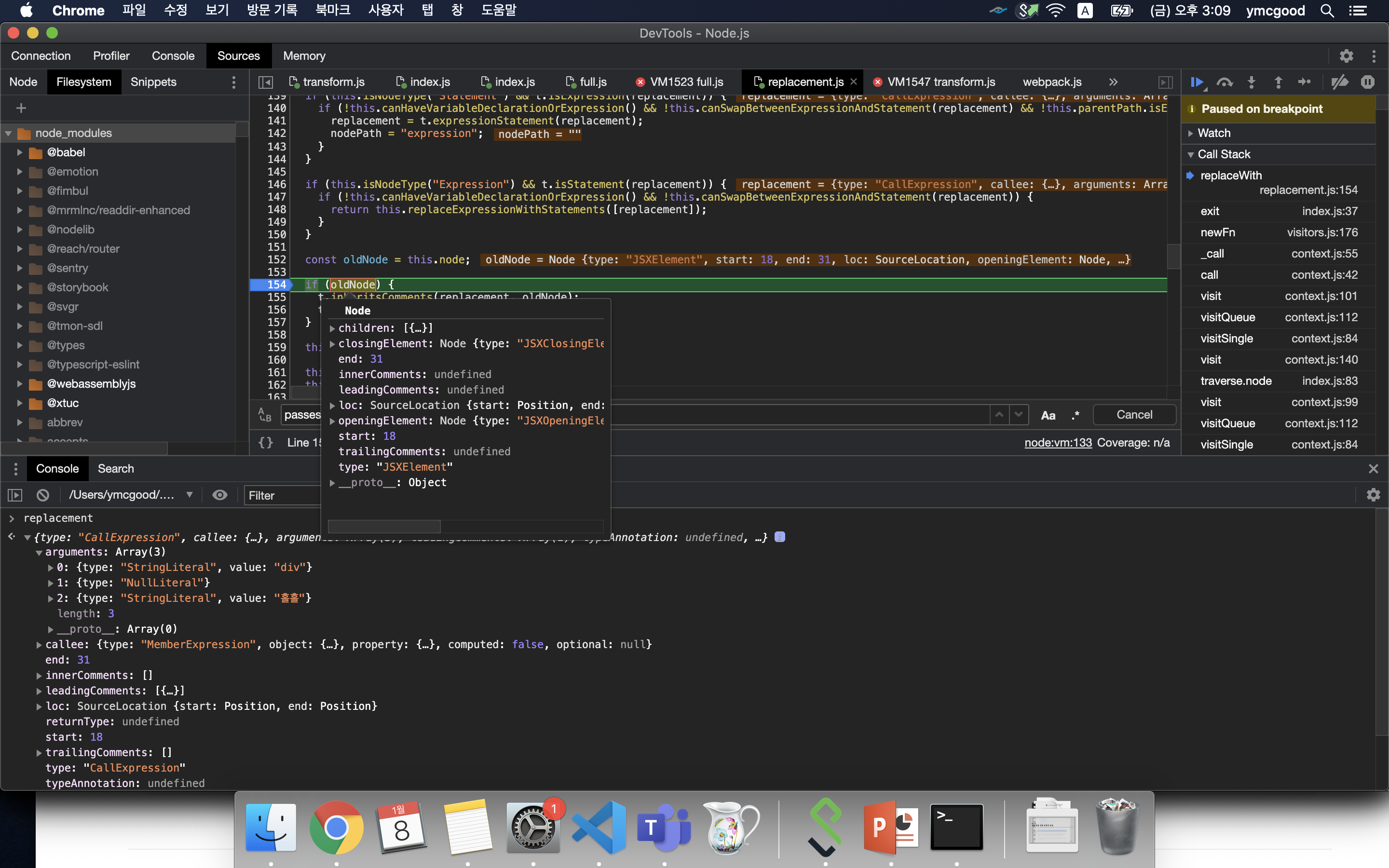
위와같이 traverse과정에서 모든노드들은 알맞은 visitor의 함수를 통해 update된다.
3. generate : 생성된 ast로 변경된 code 생성
@babel/core/lib/transformation/index.js 에서 generator의 generate호출
#generate
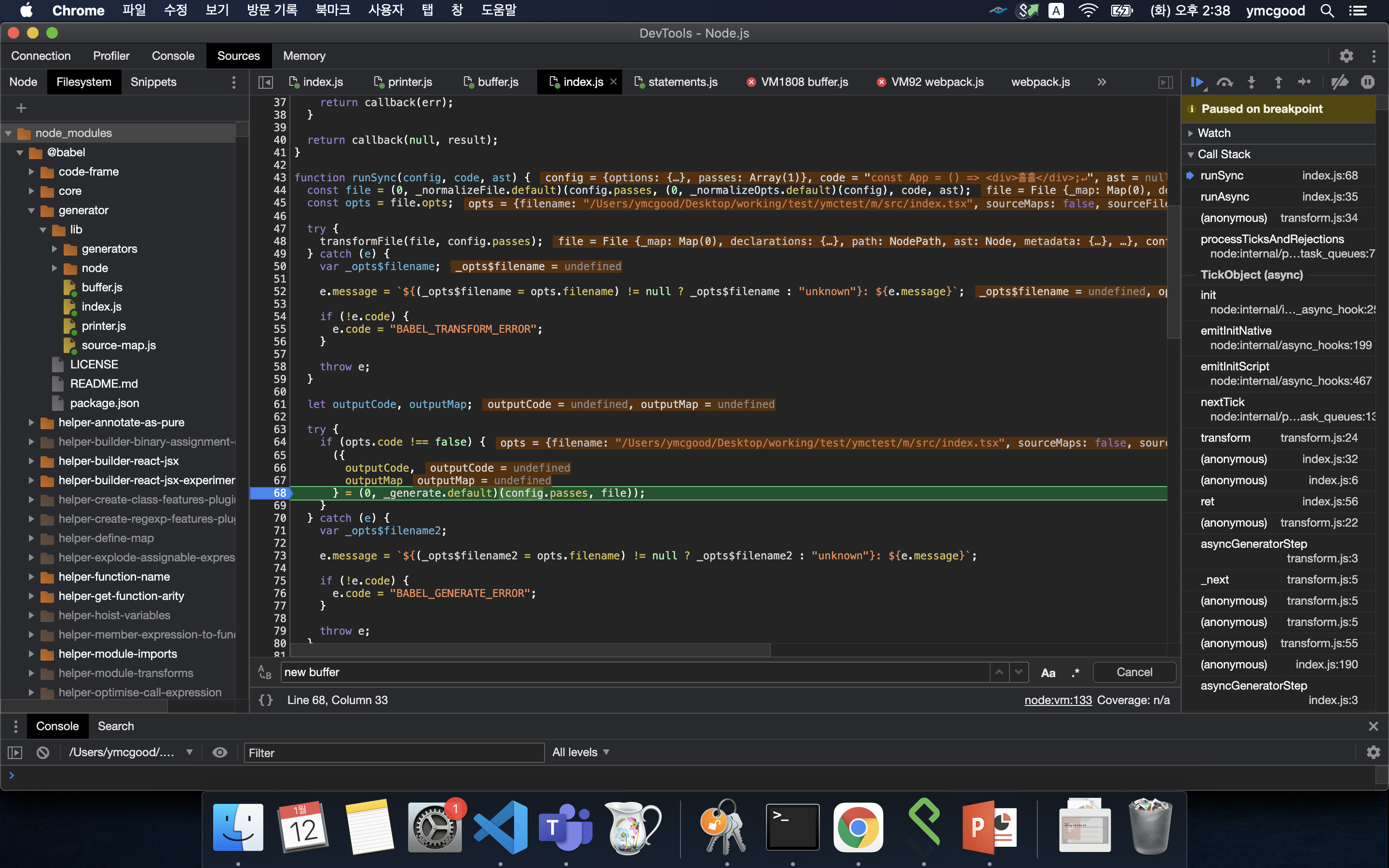
generate는 @babel/generator/lib/index.js에서 부터 시작된다.
최종적으로 반환되는 코드는 buffer객체의 _buf array를 join해서 생성한다.즉 node를 분석해가면서 변경된 코드조각들이 buffer의 _buf에 push된다. 이 동작은 _append 함수를 통해 수행된다. buffer 객체는 Printer클래스의 _buf란 프로퍼티에 할당된다.그리고 generator는 이 printer 클래스를 확장하여 사용한다.
ast의 root는 File 타입이다.
#File type node in generate
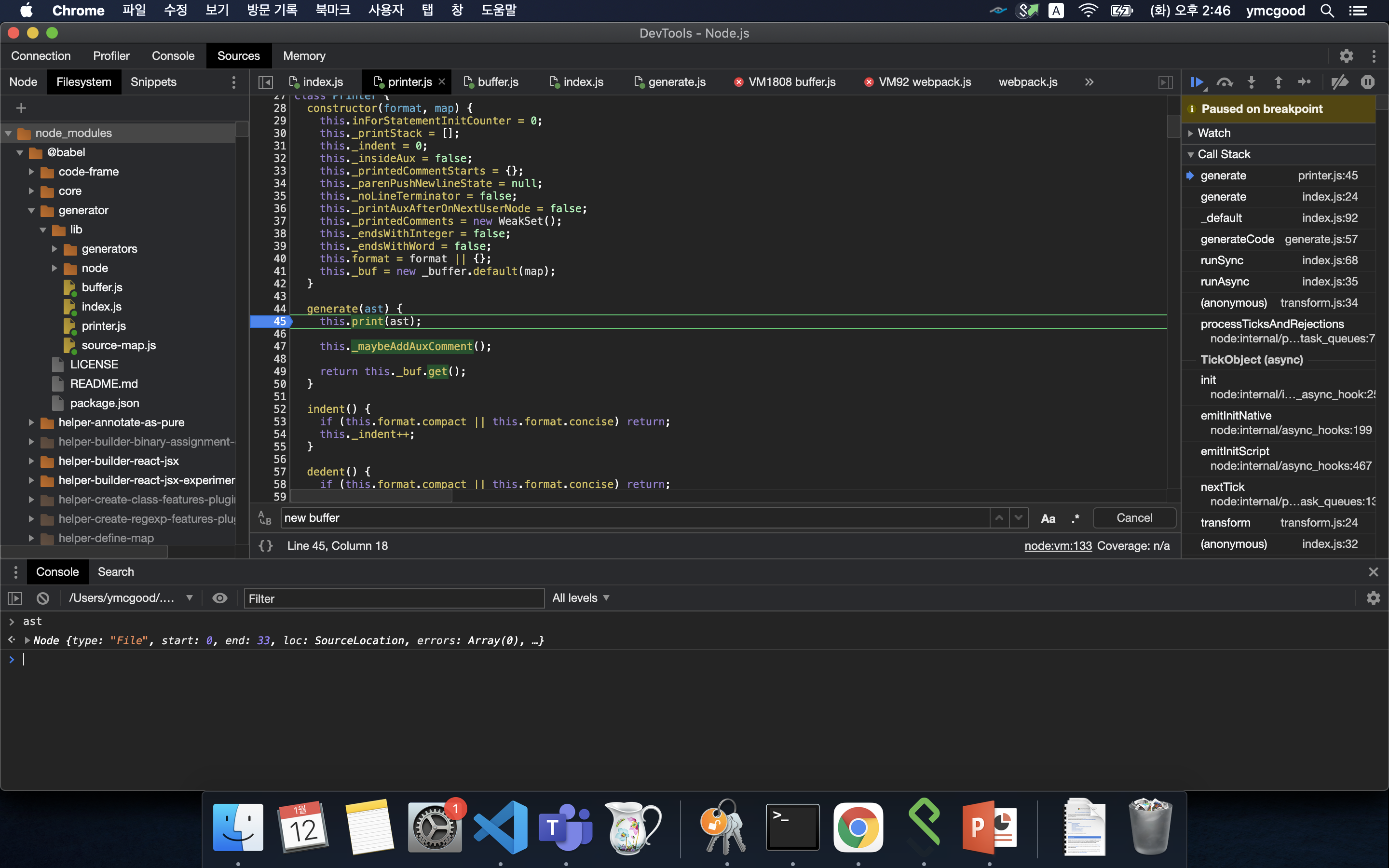
printer의 print메써드를 호출하고 이 안에서 반복적으로 다시 print를 호출하며 buffer를 채운다.
withSource함수는 map의 여부에 따라서 바로 printMethod를 호출할지 말지 결정된다. map이 있다면 추가 작업후 printMethod를 호출한다. 이 printMethod는 node의 타입과 동일한 함수명을 가진다. 예를 들면 File 타입은 Base.js에 있는 File함수를 호출한다. File 함수는 File의 자식인 Program Node를 루트로 갖는 ast를 인자로 print 메서드를 호출한다.
다음은 VariableDeclatrion 타입이다.
#print VariableDeclarion
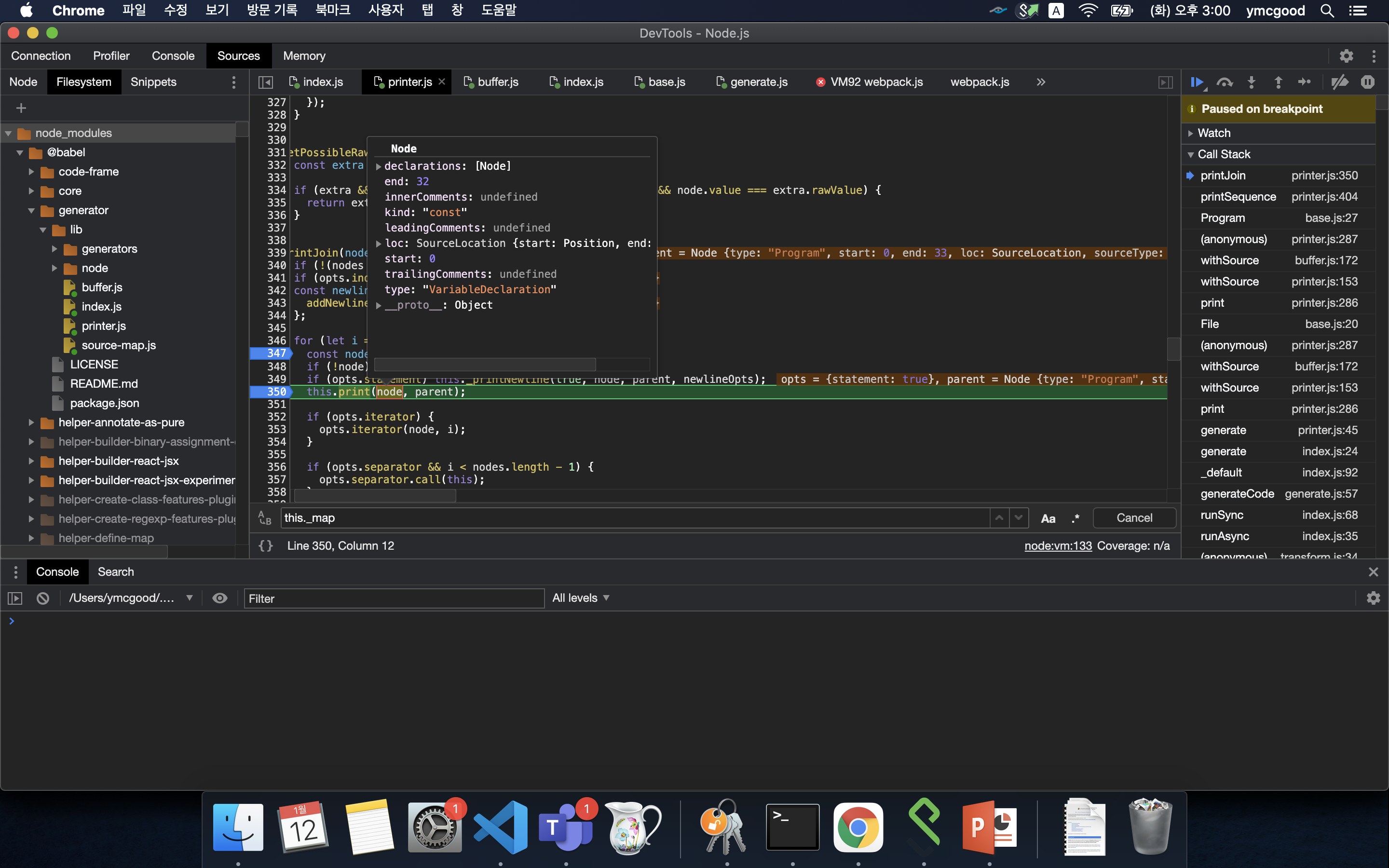
Statements.js파일의 VariableDeclatrion 함수를 통해 최초로 const가 buffer에 push됨을 알수 있다.
#VariableDeclarion method
#push const
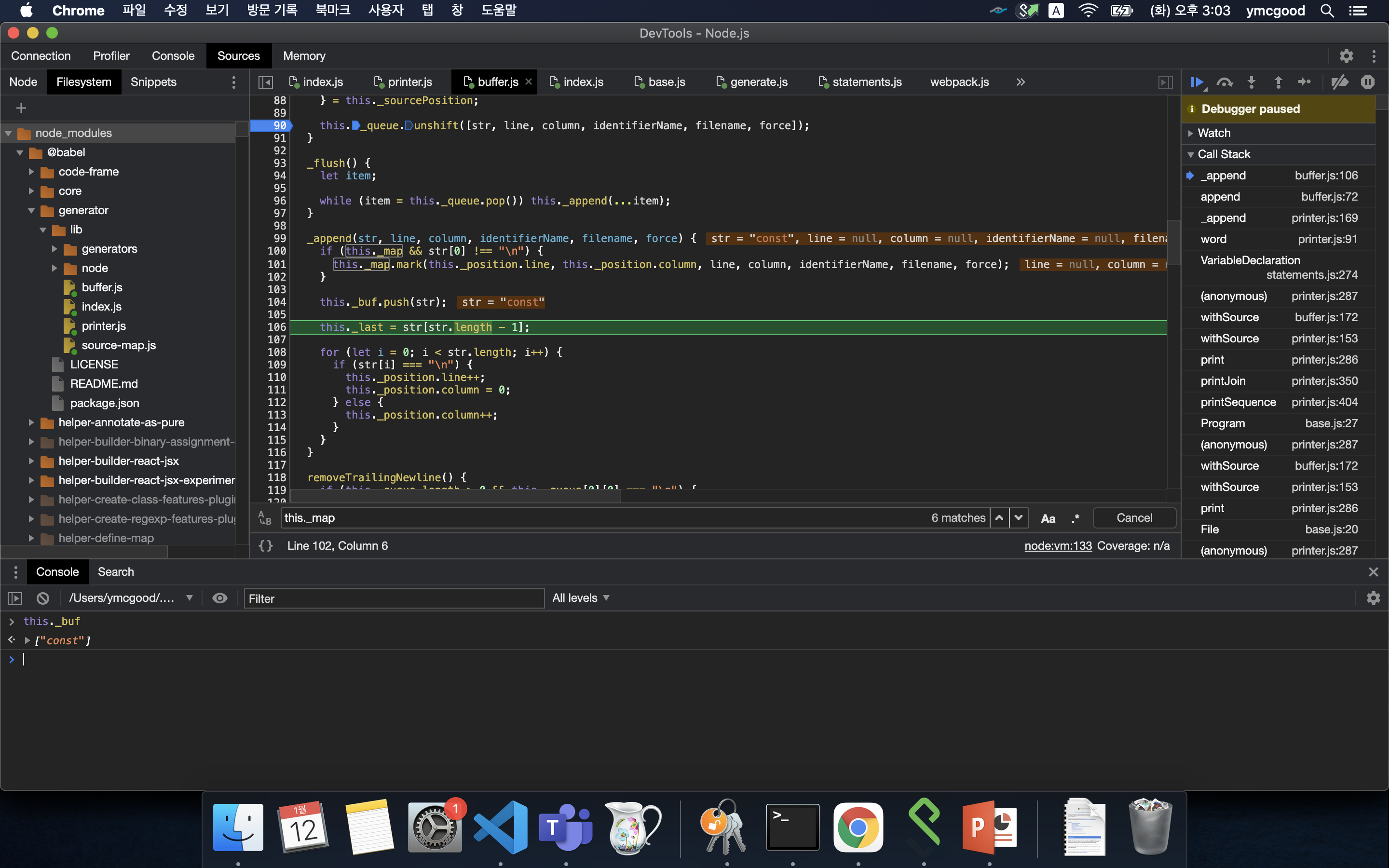
중간에 보면 this.space()가 보이는데 말그대로 buffer에 공백을 push한다.
VariableDeclatrion안에서는 node.declarations를 인자로 print함수를 호출한다. VariableDeclator -> ArrowFunctionExpression 그후 Identifier -> init -> Callexpression -> MemberExpression … 계속 각 node의 자식으로 가지고 있는 node타입의 이름으로 함수가 호출되며 buffer를 채운다. 방대한양의 case를 모두 코드로 구현해 놓았다. 각 노드에 대한 작업은 stack으로 관리된다. 새로운 node를 print하기 전에 스택에 넣어놓고 자식 node들 까지 모두 print가 끝나면 pop한다. 이 스택의 명칭은 printer 클래스에서 _printStack이다.
최종 결과물이다.
#final output
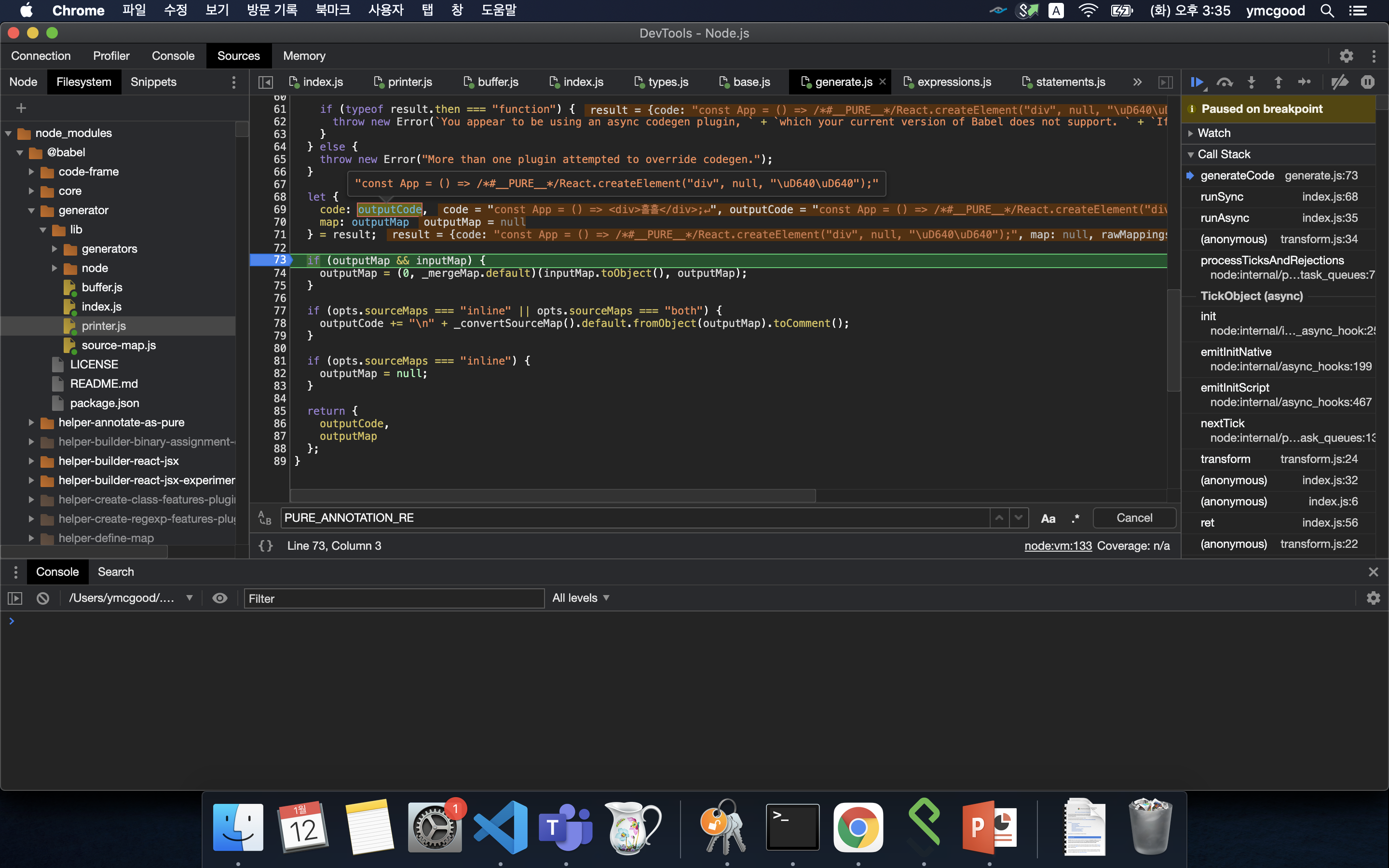
bonus : /#PURE/ annotation은 어디서 붙는걸까?
#PURE annotation
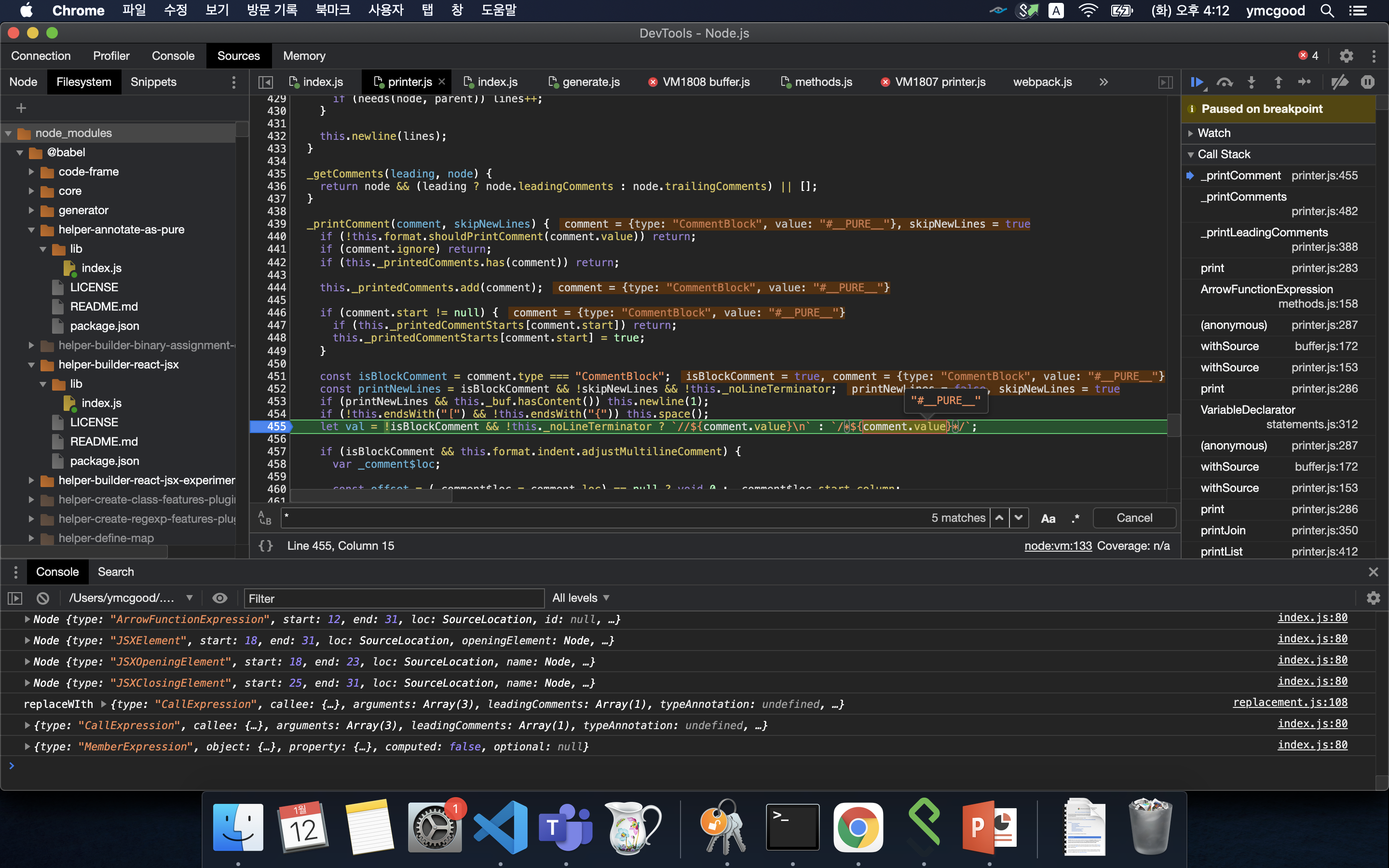 각 node를 프린트할때 leadingComments라는 프로퍼티 또한 프린트 하는데 그때 생성된다. 그러면 #__PURE__는 어디서 오는걸까? 앞서 traverse에서 언급했던 @babel/helper-builder-react-jsx을 보면 @babel/helper-annotate-as-pure를 가져다 쓰고 이 안에
각 node를 프린트할때 leadingComments라는 프로퍼티 또한 프린트 하는데 그때 생성된다. 그러면 #__PURE__는 어디서 오는걸까? 앞서 traverse에서 언급했던 @babel/helper-builder-react-jsx을 보면 @babel/helper-annotate-as-pure를 가져다 쓰고 이 안에 const PURE_ANNOTATION = "#__PURE__";로 정의되있다.
Comments